Paper Project Page
Drifting Preference Optimization for One-Step Generative Models
Online preference finetuning for deterministic one-step text-to-image generators using reward-ranked samples, dipole preference fields, and reference drift.
1Westlake University 2The Chinese University of Hong Kong, Shenzhen

Abstract
Preference optimization without likelihoods, denoising trajectories, or reward backpropagation.
One-step text-to-image generators are attractive for deployment because they generate an image with a single forward pass, but preference finetuning them remains difficult. DrPO is an online preference-finetuning method for deterministic one-step generators. For each prompt, DrPO samples candidates from the current generator, ranks them with a target reward, and uses high- and low-scoring samples to synthesize a feature-space update direction. The update combines a non-parametric dipole preference field with a reference drift estimated from the frozen base generator, and is optimized through a detached feature-space regression target. The target reward is used only for ranking, so DrPO can optimize with large, black-box, or non-differentiable rewards while inference remains a single generator call.
Method
Dipole preference drift plus reference correction.
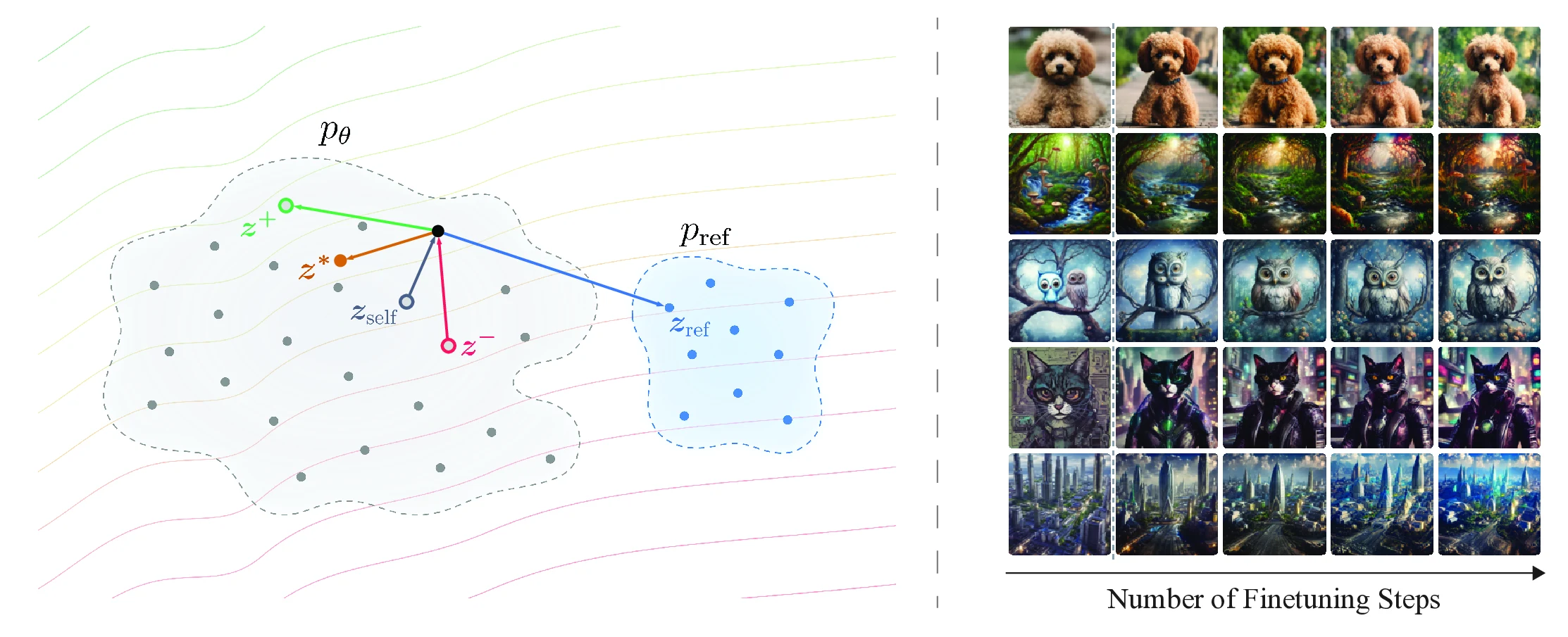
Generate on-policy candidates
For each prompt, DrPO samples a candidate set from the current one-step generator under different latent seeds.
Rank with the target reward
The reward model selects positive and negative supports. It does not need to be differentiable through the generated image.
Fit toward a detached target
Preference and reference fields define a feature-space target, and LoRA parameters are optimized with a regression loss.
Results
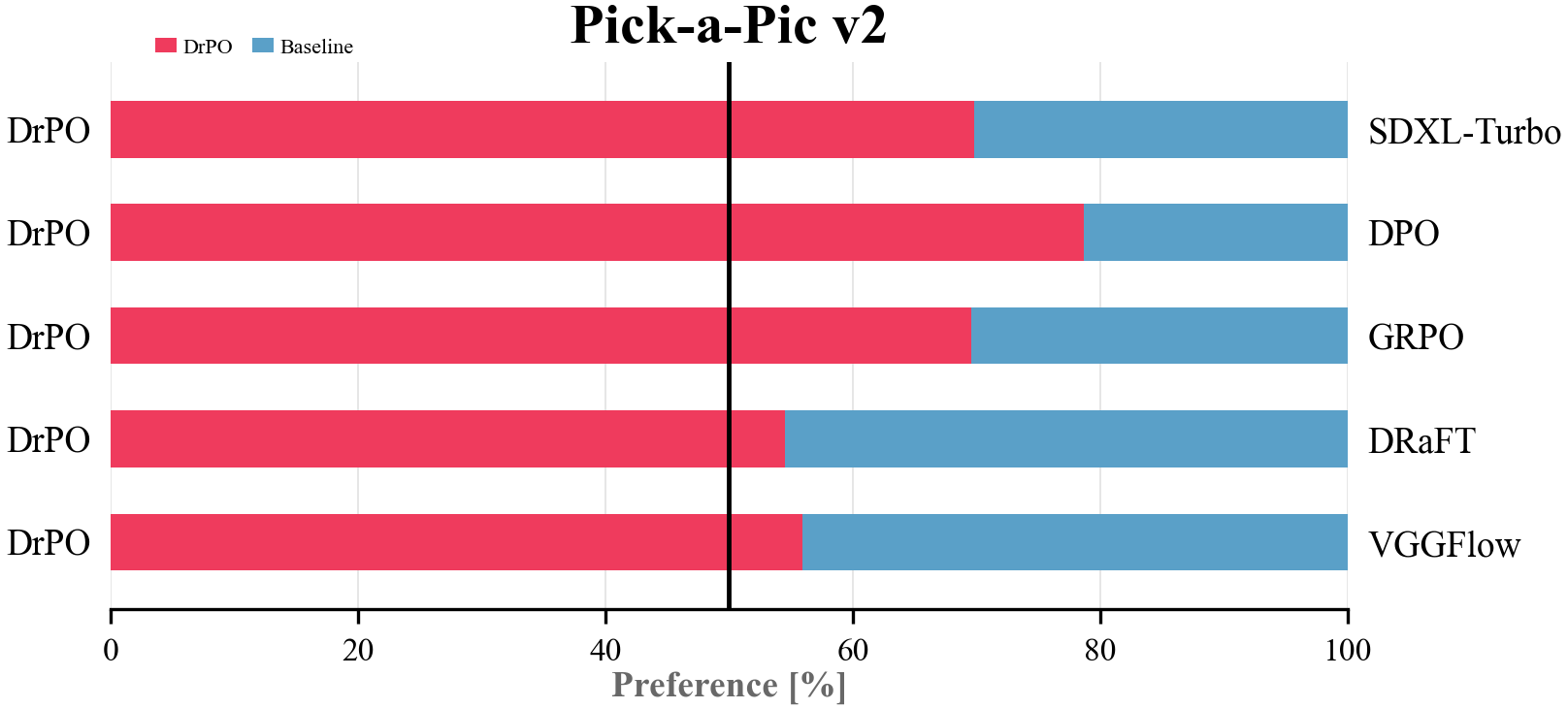
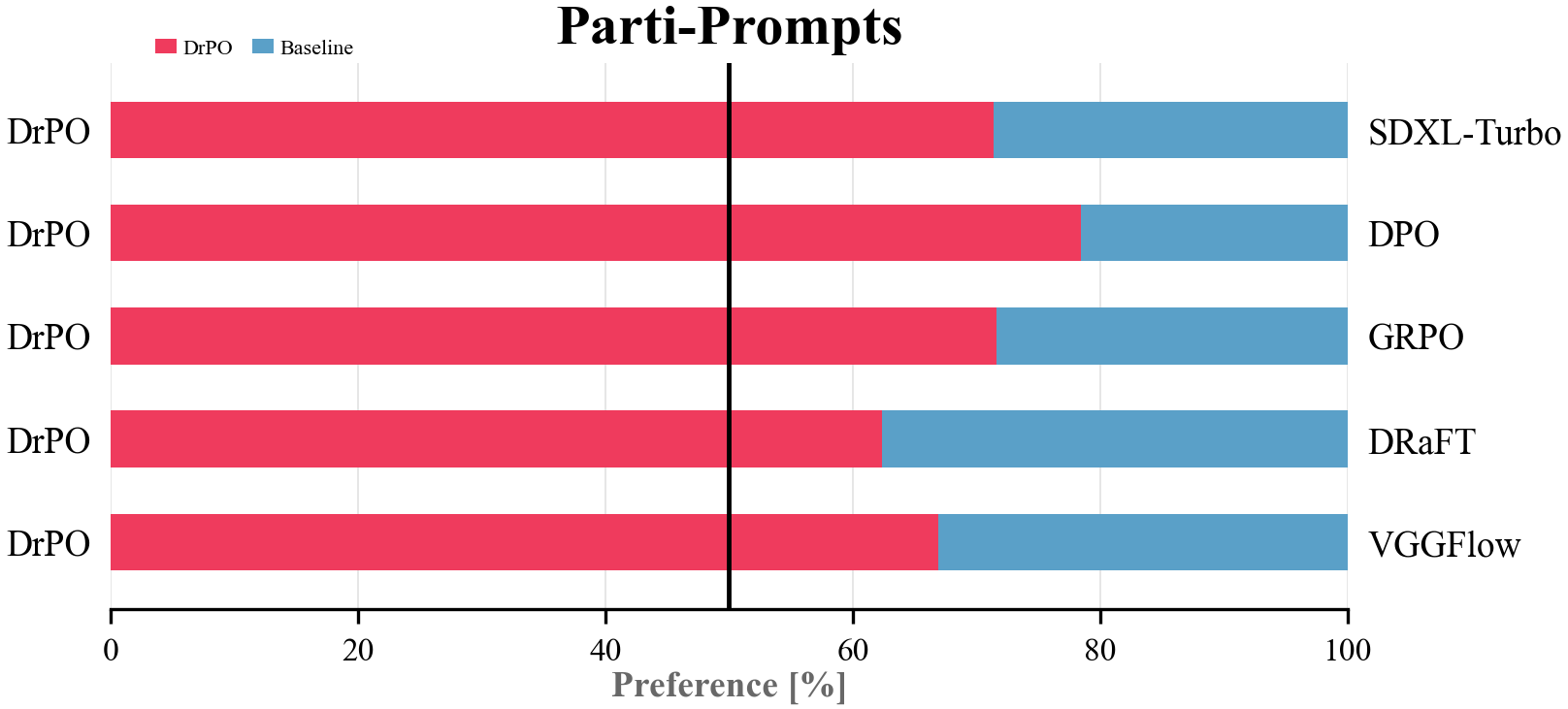
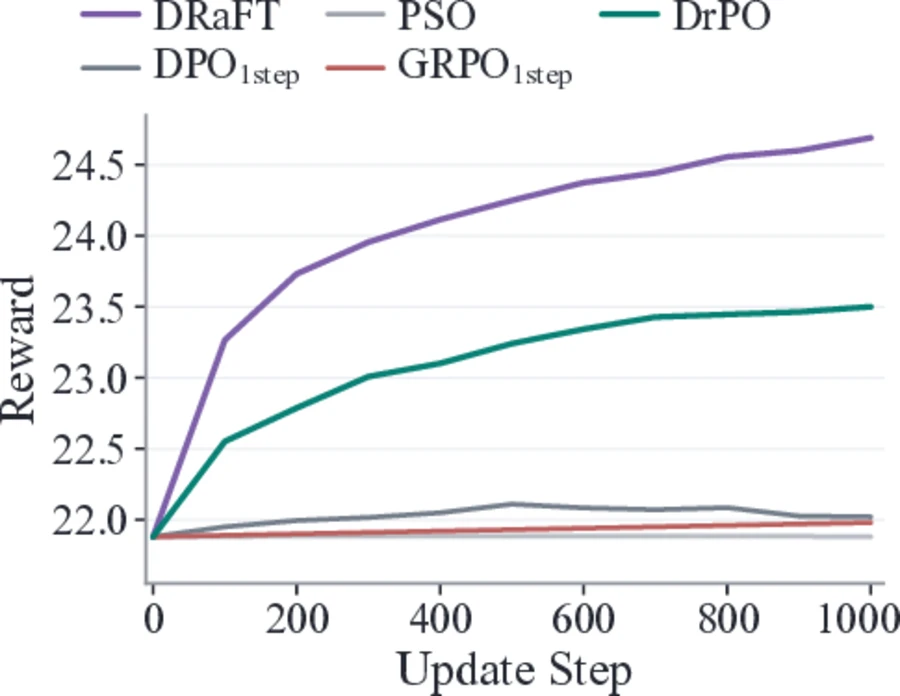
DrPO gives the largest reward-gradient-free gains among one-step preference baselines.
| Method | Steps | Reward grad. | Pick-a-Pic v2 Test | Parti-Prompts | ||||
|---|---|---|---|---|---|---|---|---|
| PS | AES | IR | PS | AES | IR | |||
| SDXL base | 50 | - | 22.15 | 6.104 | 6.85 | 22.64 | 5.761 | 7.24 |
| SDXL-DPO | 50 | - | 22.57 | 6.076 | 9.38 | 22.95 | 5.811 | 10.66 |
| SDXL-Turbo base | 1 | - | 22.45 | 6.059 | 9.36 | 22.77 | 5.693 | 9.13 |
| DRaFT | 1 | Yes | 24.45 | 6.712 | 12.70 | 24.34 | 6.485 | 12.66 |
| VGGFlow | 1 | Yes | 24.27 | 6.490 | 12.19 | 23.98 | 6.200 | 11.40 |
| DPO1step | 1 | No | 22.77 | 6.227 | 10.44 | 22.85 | 6.019 | 11.25 |
| PSO | 1 | No | 22.56 | 6.092 | 8.97 | 22.87 | 5.744 | 9.17 |
| GRPO1step | 1 | No | 22.50 | 6.077 | 9.57 | 22.80 | 5.710 | 9.27 |
| DrPO | 1 | No | 23.66 | 6.717 | 12.46 | 23.71 | 6.665 | 12.60 |
SDXL-Turbo main result
DrPO improves SDXL-Turbo from 22.45 to 23.66 PickScore, 6.059 to 6.717 AES, and 9.36 to 12.46 ImageReward on Pick-a-Pic v2.
SD-Turbo generalization
On SD-Turbo, DrPO improves PickScore from 21.88 to 23.49 and ImageReward from 5.75 to 9.54 on Pick-a-Pic v2.
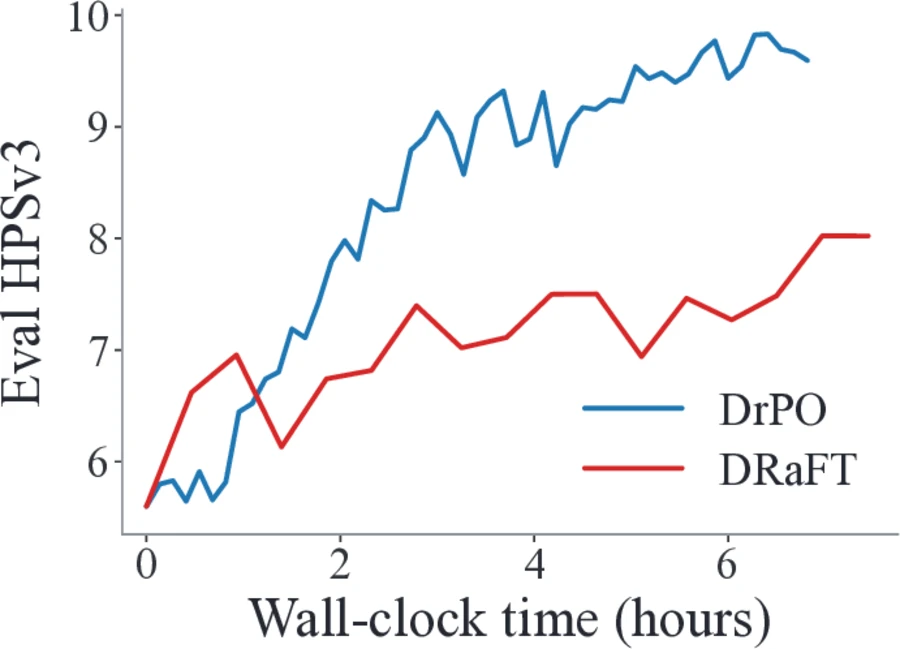
Large reward models
With HPSv3, DrPO removes reward-model backpropagation and reduces matched-batch update time from 21.62s to 6.17s.

Qualitative
Matched-prompt comparisons and reward-model ablations.
A tourist is looking at a whale using binoculars






A dolphin in an astronaut suit on Saturn






A wine bottle with a lit candle in its spout






Subway train with lobsters reading newspaper






Burger with wheels speeding on the race track, supercharged, detailed, hyperrealistic, 4K






A toy poodle







Mystical forest with glowing mushrooms and a babbling brook







A spaceship pointing up on a plain background








Extended quantitative results.
SD-Turbo transfer
| Method | Steps | Reward grad. | Pick-a-Pic v2 Test | Parti-Prompts | ||||
|---|---|---|---|---|---|---|---|---|
| PS | AES | IR | PS | AES | IR | |||
| SD1.5 | 50 | - | 20.79 | 5.455 | 1.22 | 21.49 | 5.358 | 2.25 |
| LCM-SD1.5 | 4 | - | 20.50 | 5.497 | -3.08 | 21.15 | 5.396 | -1.94 |
| SD2.1 | 50 | - | 21.09 | 5.645 | 2.49 | 21.77 | 5.547 | 3.97 |
| SD-Turbo base | 1 | - | 21.88 | 6.054 | 5.75 | 22.29 | 5.758 | 5.37 |
| DRaFT | 1 | Yes | 24.69 | 6.820 | 9.63 | 23.07 | 6.516 | 7.72 |
| VGGFlow | 1 | Yes | 23.73 | 6.378 | 7.74 | 22.99 | 6.027 | 6.50 |
| DPO1step | 1 | No | 22.02 | 6.080 | 5.95 | 22.39 | 5.793 | 5.21 |
| PSO | 1 | No | 21.88 | 6.059 | 5.80 | 22.29 | 5.763 | 5.42 |
| GRPO1step | 1 | No | 21.98 | 6.077 | 6.08 | 22.35 | 5.779 | 5.65 |
| DrPO | 1 | No | 23.49 | 6.485 | 9.54 | 22.99 | 6.284 | 7.46 |
Efficiency and robustness
| Metric | DRaFT | DrPO |
|---|---|---|
| Reward grad. | Yes | No |
| Effective batch | 192 | 192 |
| Update time (s) | 21.62 | 6.17 |
| Speedup | 1.00x | 3.51x |
| Backward (s) | 9.99 | 0.34 |
| Metric | SD-Turbo | +DrPO |
|---|---|---|
| Single | 98.8 | 100.0 |
| Two | 46.5 | 55.6 |
| Count | 33.8 | 42.5 |
| Colors | 83.8 | 87.2 |
| Position | 8.0 | 13.0 |
| Color Attr. | 9.0 | 13.0 |
| Objective | PickScore | CLIP | AES | HPSv2 |
|---|---|---|---|---|
| No reference | 23.55 | 25.88 | 6.603 | 34.85 |
| Perceptual loss | 23.42 | 25.98 | 6.455 | 34.90 |
| Ref. drift loss | 23.49 | 26.22 | 6.485 | 35.07 |
Ablations
| Candidates | PS | AES |
|---|---|---|
| SD-Turbo | 21.88 | 6.054 |
| K=16 | 23.24 | 6.409 |
| K=24 | 23.53 | 6.552 |
| K=32 | 23.57 | 6.599 |
| Feature | PS | AES |
|---|---|---|
| SD-Turbo | 21.88 | 6.054 |
| latent-MAE1 | 23.55 | 6.513 |
| latent-MAE2 | 23.50 | 6.526 |
| latent-MAE3 | 23.48 | 6.506 |
| Latent | 20.52 | 4.543 |
| VAE-dec. + DINOv2 | 22.28 | 6.252 |
| Kernel | PS | AES |
|---|---|---|
| SD-Turbo | 21.88 | 6.054 |
| Cosine | 23.63 | 6.509 |
| RBF | 23.50 | 6.590 |
| Exponential | 23.53 | 6.594 |
| Laplacian | 23.51 | 6.515 |
| Weight | PS | AES |
|---|---|---|
| SD-Turbo | 21.88 | 6.054 |
| eta=1000 | 23.51 | 6.510 |
| eta=3000 | 23.53 | 6.542 |
| eta=5000 | 23.51 | 6.485 |
| eta=10000 | 23.46 | 6.444 |